

Ao longo da minha trajetória profissional, enfrentamos diversos obstáculos durante a análise e o desenvolvimento de demandas, envolvendo tráfego de rede, banco de dados, servidores e desenvolvimento de software. A cada impedimento, fomos aprendendo a lidar com os desafios e a resolver os problemas à medida que os identificávamos.
Por isso, separei 5 dicas que podem melhorar a performance do seu banco PostgreSQL. Pode ser que algum detalhe esteja faltando e, com esses ajustes, você evite realizar um upgrade desnecessário ou até mesmo migrar para outra tecnologia, como bancos NoSQL.
1. Análise de Query
No processo de análise de queries, existem comandos nativos do PostgreSQL que facilitam (e muito) a vida de nós, meros mortais. Esses comandos não são nenhuma novidade, mas vou explicar um resumo rápido aqui:
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)ANALYZE: Mede o tempo da query por etapas, sendo possível encontrar diferenças entre a estimativa e a realidade real, como, por exemplo, cardinalidade incorreta.
COSTS: Mostra o custo estimado em cada etapa da consulta. Na prática, ela indica o caminho mais rápido (ou de menor custo) que o banco de dados utilizou para buscar os dados. É uma medida interna do próprio banco de dados.
VERBOSE: Mostra informações mais detalhadas, como colunas, nomes de tabelas e outras informações que podem ajudar na identificação e ajuste da query.
BUFFERS: Informa se os dados vieram de cache (rápido) ou do disco (mais lento). Se apresentar shared hit, é um bom sinal de que os dados vieram do cache. Se apresentar read ou temp, pode indicar gargalo ou um funil na leitura dos dados.
JSON: formata a saída dos dados, tornando-a mais legível ao visualizar.
Comando executado:
EXPLAIN (ANALYZE, VERBOSE, BUFFERS, FORMAT JSON)
SELECT DISTINCT
c.nome,
c.email,
(
SELECT COUNT(*)
FROM pedidos p2
WHERE p2.cliente_id = c.id
AND EXTRACT(YEAR FROM p2.data_pedido) = 2024
) AS pedidos_ano,
(
SELECT SUM(i.quantidade * i.preco_unitario)
FROM pedidos p3
JOIN itens_pedido i ON i.pedido_id = p3.id
WHERE p3.cliente_id = c.id
AND p3.status = 'concluido'
) AS valor_total,
(
SELECT nome
FROM produtos pr
WHERE pr.id = (
SELECT produto_id
FROM itens_pedido ip
WHERE ip.pedido_id = (
SELECT id
FROM pedidos p4
WHERE p4.cliente_id = c.id
ORDER BY p4.data_pedido DESC
LIMIT 1
)
LIMIT 1
)
) AS produto_mais_recente,
(
SELECT COUNT(*)
FROM logs_acesso la
WHERE la.cliente_id = c.id
AND la.ip ILIKE '%192.168.1.%'
) AS acessos_do_ip
FROM clientes c
INNER JOIN produto_cliente pc on pc.id_cliente = c.id
WHERE LOWER(c.nome) LIKE '%cliente%'
ORDER BY c.nome
Exemplo de retorno do PostgreSQL:
[
{
"Plan": {
"Node Type": "Sort",
"Startup Cost": 9999999.00,
"Total Cost": 10000000.00,
"Plan Rows": 100000000,
"Plan Width": 256,
"Actual Startup Time": 2100000.000,
"Actual Total Time": 2104000.000,
"Actual Rows": 10000000,
"Actual Loops": 1,
"Sort Key": ["c.nome"],
"Sort Method": "external merge",
"Sort Space Used": 2048000,
"Sort Space Type": "Disk",
"Buffers": {
"Shared Read": 25000000,
"Temp Read": 900000,
"Temp Write": 900000
},
"Plans": [
{
"Node Type": "Nested Loop",
"Join Type": "Inner",
"Actual Startup Time": 0.500,
"Actual Total Time": 2099000.000,
"Actual Rows": 10000000,
"Plans": [
{
"Node Type": "Seq Scan",
"Relation Name": "clientes",
"Alias": "c",
"Filter": "lower(nome) ~~ '%cliente%'",
"Actual Rows": 5000000,
"Buffers": {
"Shared Read": 10000000
}
},
{
"Node Type": "Seq Scan",
"Relation Name": "produto_cliente",
"Alias": "pc",
"Filter": "id_cliente = c.id",
"Actual Rows": 2,
"Buffers": {
"Shared Read": 10000000
}
}
]
}
]
},
"Triggers": [],
"Planning Time": 123.456,
"Execution Time": 2104000.789
}
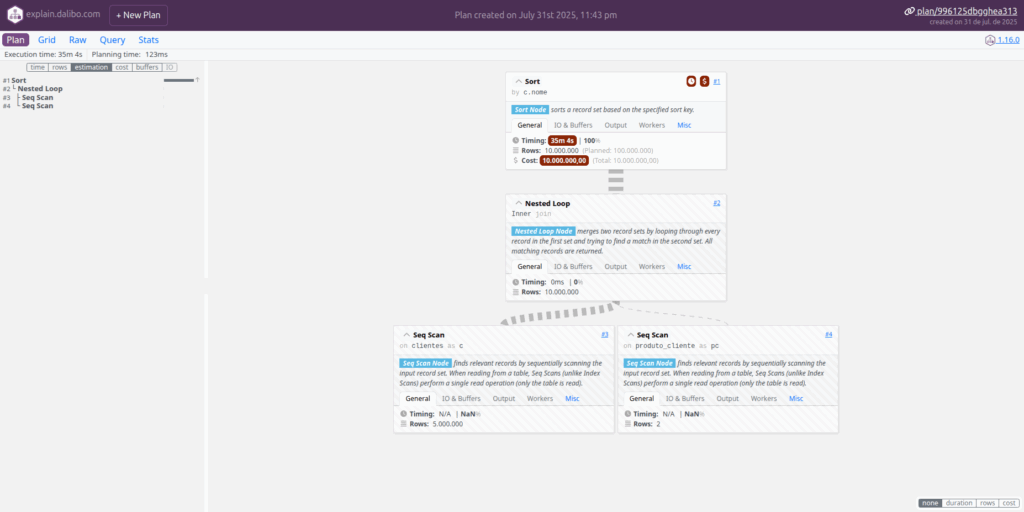
]O formato JSON é bastante técnico e, por si só, não é tão didático para análise de queries. Porém, existem ferramentas que ajudam a interpretar e organizar essas informações de forma visual, facilitando o entendimento do plano de execução
Ferramenta de Visualização: Explain Dalibo
Usando o Dalibo, é possível identificar possíveis problemas e entender o que está ocorrendo de forma didática, permitindo aplicar correções na query, como criação ou recriação de índices, particionamento de tabelas, entre outras estratégias.
Essa ferramenta é uma forte aliada no desenvolvimento de novas queries, promovendo um entendimento mais técnico e possibilitando a criação de consultas mais performáticas.
2. Monitoramento com pg_stat_statements
Hoje, no cenário atual, existem diversas ferramentas que monitoram o banco de dados, identificando queries mais lentas, quantidade de chamadas, entre outros pontos. Mas tudo isso também é possível utilizando algumas extensões no PostgreSQL:
No arquivo de configuração postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'Criação da extensão no banco:
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;Com isso, você habilita a coleta de estatísticas sobre as queries no PostgreSQL, o que permite acessar diversas informações essenciais para melhorar o desempenho do seu banco de dados. À medida que os dias passam, será possível identificar queries problemáticas com mais facilidade.
Queries com maior tempo total:
SELECT
query,
calls,
ROUND(total_exec_time / 1000, 2) AS total_exec_segundos,
ROUND(total_exec_time / NULLIF(calls, 0) / 1000, 4) AS media_exec_segundos,
ROUND(rows / NULLIF(calls, 0), 2) AS media_linhas,
ROUND(100.0 * shared_blks_hit / NULLIF(shared_blks_hit + shared_blks_read, 0), 2) AS hit_percentual
FROM pg_stat_statements
WHERE query != '<insufficient privilege>'
ORDER BY total_exec_time DESC
LIMIT 10;Queries mais chamadas:
SELECT
query,
calls,
ROUND(mean_exec_time / 1000.0, 4) AS avg_exec_seconds,
ROUND(total_exec_time / 1000.0, 2) AS total_exec_seconds,
ROUND(rows / NULLIF(calls, 0), 2) AS avg_rows
FROM pg_stat_statements
WHERE calls > 100
AND query != '<insufficient privilege>'
ORDER BY mean_exec_time DESC
LIMIT 10;Então, é possível explorar o resultado dessa query usando o EXPLAIN do PostgreSQL, mas com o Dalibo é ainda mais fácil identificar os gaps e ter um ponto de partida mais claro para melhorar a análise.
3. Análise de Índices
No decorrer dos ciclos de desenvolvimento, são criados índices para melhorar a performance. No entanto, muitas vezes as queries são modificadas, mas os índices antigos raramente são lembrados ou excluídos. Isso acontece principalmente quando não há alguém monitorando ou algum gatilho para identificar esse tipo de situação.
Consulta para verificar os índices em uso:
SELECT
schemaname, -- Nome do schema onde a tabela está localizada
relname AS table_name, -- Nome da tabela associada ao índice
indexrelname AS index_name, -- Nome do índice
idx_scan AS times_used, -- Quantas vezes esse índice foi usado em buscas
pg_size_pretty(pg_relation_size(i.indexrelid)) AS index_size -- Tamanho do índice, formatado de forma legível (ex: MB, GB)
FROM
pg_stat_user_indexes ui -- Exibe estatísticas de uso de índices criados pelo usuário
JOIN
pg_index i ON ui.indexrelid = i.indexrelid -- Junta com pg_index para obter mais informações técnicas do índice
WHERE
idx_scan > 0 -- Filtra apenas os índices que foram utilizados pelo menos uma vez
ORDER BY
idx_scan DESC; -- Ordena pelos índices mais usados primeiroPara encontrar índices nunca usados, utilize:
WHERE idx_scan = 04. Particionamento de Tabelas
Normalmente, quando se tem uma tabela muito grande com fluxo constante de inserções e alterações, o ideal é particioná-la em várias fatias menores. Isso não serve apenas para melhorar as operações de inserção ou seleção (SELECT), mas também para organizar melhor os dados.
Um exemplo comum de particionamento envolve o uso de colunas como empresa, ano, mês ou semestre, o que contribui para uma modelagem de dados mais madura e eficiente.
CREATE TABLE pedidos (
id SERIAL,
cliente_id INT,
data_pedido DATE,
status TEXT
) PARTITION BY RANGE (data_pedido);
CREATE TABLE pedidos_2023 PARTITION OF pedidos
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');Um dos pontos mais importantes é que as partições da tabela precisam ser criadas manualmente. Não existe um mecanismo nativo que crie as partições automaticamente. Em muitos casos, quando a equipe não possui alguém dedicado à administração do banco de dados, esse processo acaba sendo negligenciado.
Com a rotatividade de pessoas na equipe, determinados fluxos, se não estiverem bem documentados, podem cair em uma área de incerteza, conhecida apenas por membros mais antigos. Com o tempo, esse conhecimento se perde, e o resultado, após alguns meses, pode ser o inchaço da estrutura da tabela, causando lentidão generalizada.
Nesse cenário, embora não seja a solução ideal, é possível contornar o problema com uma abordagem funcional até que o PostgreSQL implemente algo nativo: criar uma função responsável por gerar a partição dinamicamente, acionada por uma trigger no momento da inserção.
Observação: Na primeira inserção, pode haver um pequeno atraso entre 1 e 30 segundos, dependendo do hardware do banco de dados.
Nos testes realizados em ambiente controlado: Para tabelas com menos de 1 milhão de linhas, o tempo médio para criação da partição foi de aproximadamente 500 milissegundos. Para tabelas com mais de 20 milhões de linhas, esse tempo pode chegar a 3 segundo na primeira criação. É sempre importante considerar a capacidade e performance do hardware do banco de dados ao utilizar essa abordagem.
Exemplo de query:
CREATE TABLE eventos (
id SERIAL,
data_evento DATE NOT NULL,
descricao TEXT
) PARTITION BY RANGE (data_evento);
CREATE OR REPLACE FUNCTION cria_particao_evento(data_evento DATE)
RETURNS void AS $$
DECLARE
nome_particao TEXT := format('eventos_%s', to_char(data_evento, 'YYYY_MM'));
data_inicio DATE := date_trunc('month', data_evento);
data_fim DATE := (date_trunc('month', data_evento) + interval '1 month');
BEGIN
IF NOT EXISTS (
SELECT FROM pg_tables WHERE tablename = nome_particao
) THEN
EXECUTE format($f$
CREATE TABLE IF NOT EXISTS %I PARTITION OF eventos
FOR VALUES FROM (%L) TO (%L)
$f$, nome_particao, data_inicio, data_fim);
END IF;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION trigger_eventos_insert()
RETURNS TRIGGER AS $$
BEGIN
PERFORM cria_particao_evento(NEW.data_evento);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER tg_eventos_insert
BEFORE INSERT ON eventos
FOR EACH ROW
EXECUTE FUNCTION trigger_eventos_insert();
5. Integração com postgres_fdw
Essa é uma das aplicações mais interessantes que o PostgreSQL oferece e pode facilitar migrações em que é necessário desacoplar sistemas gradualmente. Esse módulo conecta dois ou mais bancos de dados distintos, permitindo executar SELECT no banco principal e consultar tabelas em bancos secundários que são totalmente independentes. Tudo isso é feito como se o acesso ocorresse dentro de um único banco de dados, o que facilita bastante o trabalho das equipes de desenvolvimento.
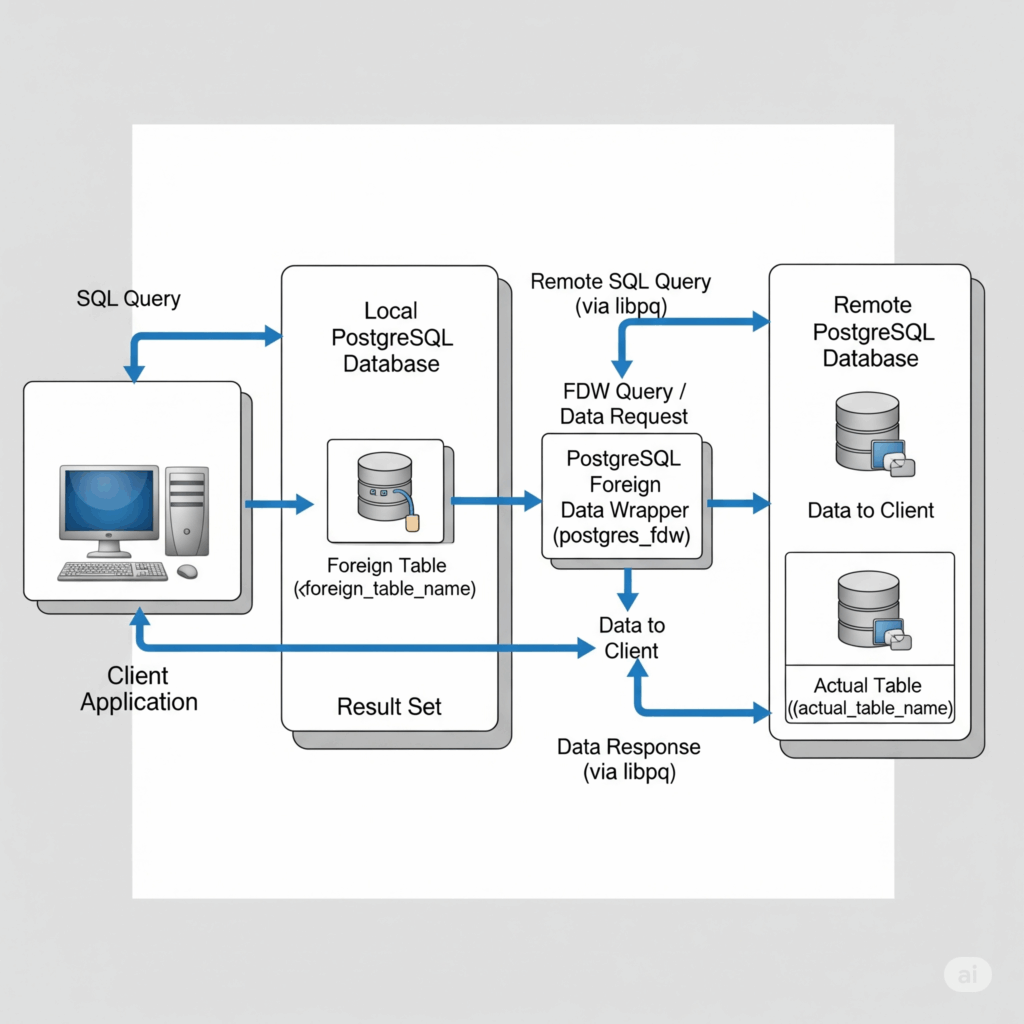
Cuidados no uso: Nesse cenário, algumas precauções precisam ser consideradas. Dependendo da latência entre os bancos de dados, pode haver lentidão nas consultas, especialmente quando há relacionamento entre tabelas distribuídas em bancos diferentes.
Exemplo:
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
CREATE SERVER servidor_remoto
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '192.168.1.10', dbname 'sistema_remoto', port '5432');
CREATE USER MAPPING FOR CURRENT_USER
SERVER servidor_remoto
OPTIONS (user 'usuario_remoto', password 'senha123');
IMPORT FOREIGN SCHEMA public
FROM SERVER servidor_remoto
INTO public;Conclusão:
Não existe um parâmetro mágico que resolva todos os problemas. No entanto, ao analisar cada cenário individualmente, é possível melhorar a qualidade e a performance do banco, utilizando as ferramentas e os meios corretos para alcançar o objetivo.